
Spreadsheets are a very popular way to organize and store information from financial reports to customer reviews. Every day we go on Reddit or Twitter, we see several people asking about this topic so we thought we would add our 2 cents. For most of this blog, we will talk about CSVs as a common type of spreadsheet, but the concepts within the blog apply to different types of structured data including JSON objects. Many of the capabilities discussed below are supported by Neum AI where you can build robust and scalable data pipelines to process data into vector embeddings. Feel free you reach out to with any questions to founders@tryneum.com or schedule time.
Connecting my spreadsheets to an LLM
Let's imagine you have a bunch of spreadsheets that contain key information about your business. On a consistent basis, you are building reports that help you visualize the data as well as feeding those spreadsheets into existing ML models to crunch through the number. LLMs have the potential to help automate several of those actions to get more insights faster and with less hassle. But how LLMs can help varies on the type of data we have at hand and the desired output. On one hand we might have spreadsheets full of numerical data like revenue numbers, growth percentages, or dates and times. On the other we might have spreadsheets that contain content like user reviews, product listings, etc. LLMs can serve different roles across these different types of data that is driven by the types of questions that we want to extract from them.
Spreadsheets with numerical data
For these types of spreadsheets, examples of questions might be something like:
- Who are the top five customers by revenue?
- What was the growth of the company in the last month?
- What customers decreased their spend in the last week in Spain?
At the same time the data to answers these questions requires a number of transformations like sums, counts, filters that are very aligned to traditional Datalytics. For this use case, LLMs provide value in:
- Helping query the data. LLMs can help translate a question into a query that can run on top of the data. For example, who are the top five customers by revenue might translate to order customers by revenue and limit to 5.
- The queried data (up to the token limit) can be fed into an LLM prompt as a table that it can use as context to respond questions.
Spreadsheets with content
In the case of content, for example product listings or customer reviews, querying data in a traditional manner is more difficult as the value in the content lies on its semantic nature. You can’t use traditional queries alone to answer questions like:
- Show me products that are similar to X?
- Does product Y work well?
- What are positive features that users find with our product?
These questions require us to match the question to the data based on their semantic representation. For example, saying does product Y work well, is not a Boolean that we likely have in the data, instead we need to search through reviews from users to get a general sense of what they are trying to tell us. LLMs really shine for this use case as they enable capabilities that were otherwise hard to achieve with more traditional ML models.
To enable this use case, we can use embeddings and vector databases to index our content within the spreadsheet so we can search on top of it. For the rest of this blog, we will focus on the this use case 🙂.
What do I do with all these columns of data?
Let's imagine for a second that we have a spreadsheet that contains product listings:
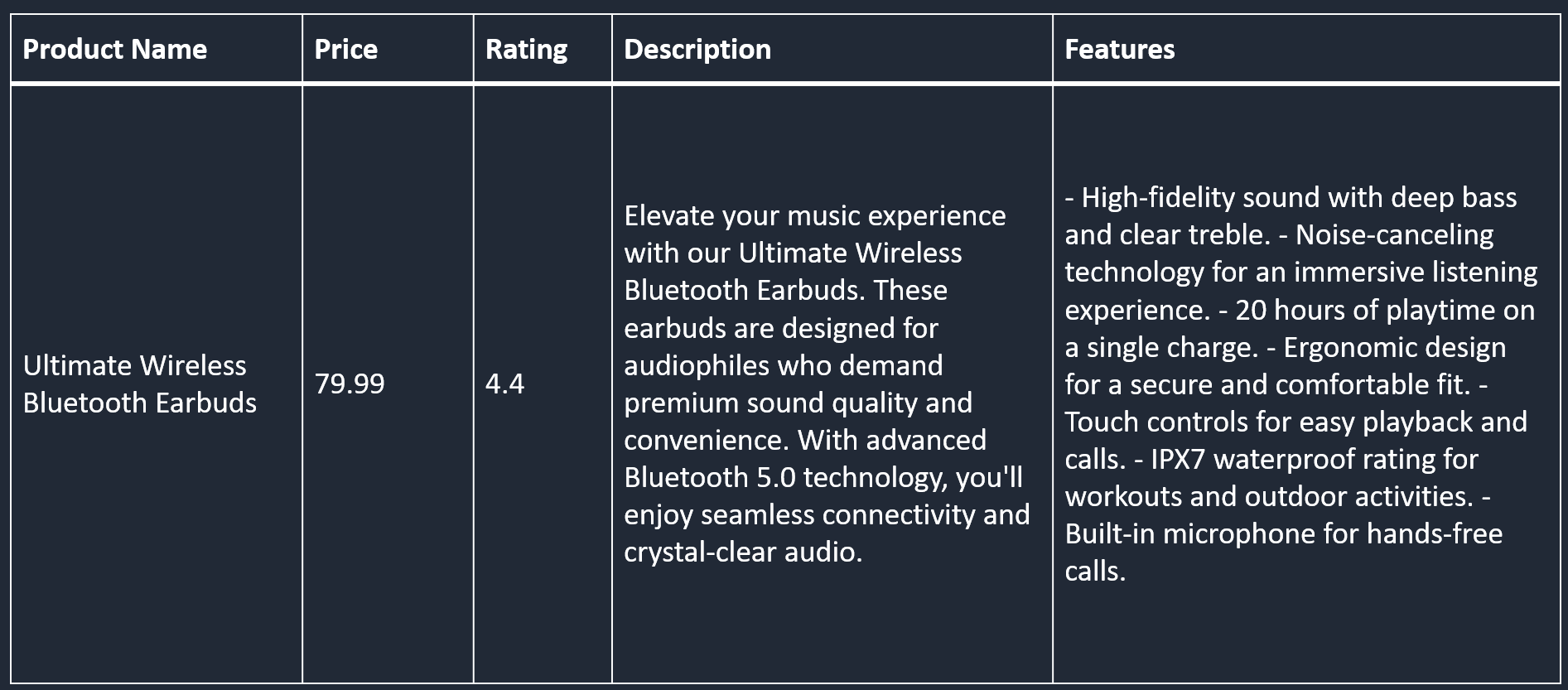
For each product listing we have information, including their names, prices, ratings, descriptions, and features. From this listings, we will focus our attention of the description and features. These columns contain the most semantically relevant information that we want to match user queries to. Columns like price and ratings, provide almost no semantic meaning and therefore we will simply use as metadata for our vectors.
The end result is that we will organize our data into a vector database with:
- A vector of the content found within the semantically relevant columns (i.e. description and features in vector form)
- Some metadata associated to the vector that we can retrieve with the vector to pass as context to the application. (i.e. name, price, rating, description text and features text)
Example vector:
How would it work?
Let's look at code to put this theory into action. We will use Langchain to help us with text splitting and loading into vector databases. We will use Chroma as our vector database running locally, but this can swapped to any other hosted vector database you might like. To download the sample listings CSV that we will use, download here.
Ingesting the data into vector databases
We will start by importing the tools we will use including the CharacterTextSplitter , OpenAIEmbeddings and Chroma .
Next, we will open the CSV file we have with our test listings. For each row in it we will separate the columns we will use for embeddings and those that we will use as metadata. We will use the Langchain Document construct to organize our content and metadata.
Once we have the document created, we will use the Langchain CharacterTextSplitter to break them further down into chunks.
Now that we have the chunks, we will generate the embeddings and insert the values into Chroma. Each vector inserted will have both the vector representation that will be used for similarity search as well as the metadata values we added.
Finally, we can query the data and even pass in filters to leverage the metadata we have associated.
Advanced Querying
To really take advantage of that metadata we generated, we can go beyond and leverage the Langchain SelfQueryRetriever. We can define a schema for the metadata easily and have it been used to generated filters using LLMs.
Scaling up the process
At this point, we have a basic version of the workflow working, but you might be asking yourself how you would productize it further. Maybe you have hundreds or thousands of CSVs that you want to process, or you have CSVs that are continuously being updated and want to ensure that your vectors are kept up to date. Also at retrieval, you might be looking at ways of automating the metadata schema creation and maintenance process. These same questions might apply to other data types like JSONs.
If these are questions you are trying to figure out, Neum AI can help. We have built a scalable and robust platform that helps process your data into vector embeddings inside of a vector database and keep them up-to-date even as your data source is changing. When it is time to retrieve, we provide a schema automatically that you can use yourself or plug into Langchain SelfQueryRetriever. See it all in action in this video.
If you would like to learn more head over to Neum AI or schedule time with me to show you a demo.

.png)



